
DevSSOM
파이썬 pandas - 데이터프레임 본문
반응형
데이터프레임 (DataFrame)
여러 개의 Series가 모여서 행과 열을 이룬 데이터. 시리즈 데이터는 하나의 컬럼 값으로 이루어진 반면 데이터 프레임은 여러 개의 컬럼 값을 가질 수 있음.
데이터프레임 만들기
1) 딕셔너리 -> 시리즈 -> 데이터프레임
cf. 시리즈를 만들 때 꼭 딕셔너리로 먼저 만들어야 되는 건 아님. Series([1, 2, 3, 4]) 이렇게 바로 시리즈로 만들 수도 있음.
import pandas as pd
# 딕셔너리 -> 시리즈 데이터로 만들기
population_dict = {
'korea' : 5180,
'japan' : 12718,
'china' : 141500,
'usa' : 32676
}
population = pd.Series(population_dict)
gdp_dict = {
'korea': 169320000,
'japan': 516700000,
'china': 1409250000,
'usa': 2041280000,
}
gdp = pd.Series(gdp_dict)
# 시리즈 -> 데이터프레임으로 만들기
country = pd.DataFrame({
"gdp" : gdp,
"population" : population
})
print(country)
# Country DataFrame
# population gdp
# korea 5180 169320000
# japan 12718 516700000
# china 141500 1409250000
# usa 32676 2041280000나라 이름은 인덱스로 들어가고, 인덱스 다음엔 gdp, population이 컬럼에 들어가게됨.
2) 딕셔너리 -> 데이터프레임 (시리즈를 거치지 않고 바로 데이터프레임 만들기)
import pandas as pd
data = {
'country' : ['korea', 'japan', 'china', 'usa'],
'gdp' : [169320000, 516700000, 1409250000, 2041280000],
'population' : [5180, 12718, 141500, 32676]
}
country = pd.DataFrame(data) # 여기까지 하면 인덱스는 0 1 2 3 이렇게 숫자로 설정됨
country = country.set_index('country') # 이렇게 하면 인덱스가 country로 설정됨
헷갈릴까봐 정리해보면
- (1) 딕셔너리 : 중괄호로 표시 {}. data = {key : value}
- (2) 시리즈 : series([1, 2, 3, 4])
- (3) 데이터프레임 : 앞에는 인덱스, 뒤에는 시리즈 데이터
- (1) -> (2) 가능, (2)를 만들 때 꼭 (1)을 거쳐야하는 것은 아님. (2) -> (3) 가능, (1) -> (3)도 가능.
데이터프레임 속성
1) DataFrame의 속성을 확인하는 방법
# ... 위에 코드 이어서
print(country.shape) # (4, 2)
print(country.size) # 8
print(country.ndim) # 2
print(country.values)
# [[ 5180 169320000]
# [ 12718 516700000]
# [ 141500 1409250000]
# [ 32676 2041280000]]county.shape의 값이 왜 (4, 2)일까? 데이터프레임 = 데이터 + 프레임. 그 중 프레임의 역할을 하는 건 인덱스와 컬럼이라고 생각하면 되는데, 그 프레임 안에 들어가는 것이 데이터. 즉, values. 그래서, 이 values만 놓고 shape를 보는거.
2) 인덱스와 컬럼에 이름을 지정하는 방법
country.index.name = "Country" # 인덱스에 이름 지정
country.columns.name = "Info" # 컬럼에 이름 지정
print(country.index)
# Index(['korea', 'japan', 'china', 'usa'], dtype='object', name='Country')
print(country.columns)
# Index(['gdp', 'population'], dtype='object', name='Info')
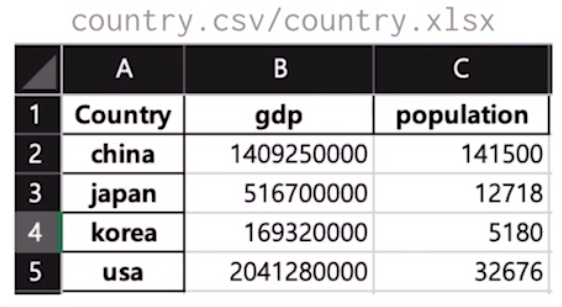
데이터프레임 저장, 불러오기
# 저장하기
country.to_csv("./country.csv")
country.to_excel("country.xlsx")
# 불러오기
country = pd.read_csv("./country.csv")
country = pd.read_excel("country.xlsx")여기서 csv는 Comma Separated Value라고 해서 콤마로 분리된 텍스트 값들을 의미. 이렇게 저장해서 읽어들인 값은 데이터프레임 형태이기 때문에 아래처럼 보여짐. (행 순서는 살짝 다름ㅠ 귀찮아서)
728x90
반응형
'Python > 기초' 카테고리의 다른 글
| 파이썬 pandas - 데이터프레임 분석용 함수 (0) | 2021.07.26 |
|---|---|
| 파이썬 pandas - 데이터프레임 정렬하기 (0) | 2021.07.26 |
| 파이썬 pandas - 데이터프레임의 데이터 선택, 추가, 수정하기 (0) | 2021.07.26 |
| 파이썬 pandas - Series 데이터 (0) | 2021.07.26 |
| 파이썬 Numpy - 배열의 인덱싱과 슬라이싱 (0) | 2021.07.26 |
| 파이썬 Numpy - 배열의 기초 (0) | 2021.07.26 |
| 파이썬 Numpy - 개념 (0) | 2021.07.24 |
'Python/기초' 관련 글
more

댓글