
DevSSOM
파이썬 크롤링 실습 - 뉴스기사 목록의 내용 수집하기 본문
반응형
뉴스기사 목록의 내용 수집하기
수집하는 페이지에 연동되어 있는 href를 추출하여 href 주소에 있는 내용을 크롤링해보기.
이전의 실습들은 언론 기사의 href만 크롤링했다면, 이번에는 각 기사의 내용까지 수집하는 것까지 실습.
사용 url : https://news.sbs.co.kr/news/newsflash.do?plink=GNB&cooper=SBSNEWS
SBS 뉴스 최신/속보
대한민국 뉴스의 기준, 중심을 지키는 저널리즘 SBS뉴스 - 시청자의 눈높이에 맞는, 더욱 품격 있는 뉴스를 제공합니다.
news.sbs.co.kr
출력 예시
[“href로 연결된 기사 내용1”, “href로 연결된 기사 내용2”, ——]
해야할 것
- 각 기사의 href를 리스트로 반환하는 get_href 함수를 올바르게 구현하기.
- get_href에서 얻은 각각의 href로 접근할 수 있는 기사의 내용을 추출하여 반환하는 crawling 함수 구현.
import requests
from bs4 import BeautifulSoup
def crawling(soup) :
# soup 객체에서 추출해야 하는 정보를 찾고 반환
# 각각의 href 페이지에 들어있는 기사 내용을 반환
return None
def get_href(soup) :
# soup 객체에서 추출해야 하는 정보를 찾고 반환
# 상위 페이지에서의 href를 찾아 리스트로 반환
return None
def main():
list_href = []
list_content = []
url = "https://news.sbs.co.kr/news/newsflash.do?plink=GNB&cooper=SBSNEWS"
req = requests.get(url)
soup = BeautifulSoup(req.text, "html.parser")
list_href = get_href(soup)
print(list_href)
for url in list_href :
href_req = requests.get(url)
href_soup = BeautifulSoup(href_req.text, "html.parser")
result = crawling(href_soup)
list_content.append(result)
print(list_content)
if __name__ == "__main__":
main()
>>>

먼저, 크롬 개발자 도구로 SBS뉴스 웹 페이지의 HTML을 확인해보면, 기사목록에 있는 각 기사의 링크는 <a class="news">에 있고, 이 <a>태그는 <div class="w_news_list type_issue">에 속해있어.
일단, 링크를 추출하는 것부터 코드 작성.
def get_href(soup) :
# soup 객체에서 추출해야 하는 정보를 찾고 반환
# 상위 페이지에서의 href를 찾아 리스트로 반환
div = soup.find("div", class_="w_news_list type_issue")
for a in div.find_all("a", class_="news"):
print(a["href"])
실행해보니까 링크가 잘려서 나와. 그래서 "https://news.sbs.co.kr"를 앞에 붙여주고, 결과값들을 리스트 안에 넣어주기.
def get_href(soup) :
# soup 객체에서 추출해야 하는 정보를 찾고 반환
# 상위 페이지에서의 href를 찾아 리스트로 반환
div = soup.find("div", class_="w_news_list type_issue")
result = []
for a in div.find_all("a", class_="news"):
result.append("https://news.sbs.co.kr" + a["href"])
return result
그럼 이제, 기사의 내용들을 크롤링해볼 차례.
기사를 클릭해서 기사 전문 페이지로 넘어가 다시 개발자 도구로 HTML을 봐보면,

각 기사의 내용은 <div class="text_area">태그에 있음.
def crawling(soup) :
# soup 객체에서 추출해야 하는 정보를 찾고 반환
# 각각의 href 페이지에 들어있는 기사 내용을 반환
div = soup.find("div", class_="text_area")
print(div.get_text())
그러면 기사 목록에 있었던 10개의 기사의 내용이 하이퍼링크들 밑으로 쭉쭉쭉 나옴.
결과값들을 리스트에 넣는 것 까지 해보면
최종 코드는
import requests
from bs4 import BeautifulSoup
def crawling(soup) :
# soup 객체에서 추출해야 하는 정보를 찾고 반환
# 각각의 href 페이지에 들어있는 기사 내용을 반환
div = soup.find("div", class_="text_area")
result = div.get_text()
return result
def get_href(soup) :
# soup 객체에서 추출해야 하는 정보를 찾고 반환
# 상위 페이지에서의 href를 찾아 리스트로 반환
div = soup.find("div", class_="w_news_list type_issue")
result = []
for a in div.find_all("a", class_="news"):
result.append("https://news.sbs.co.kr" + a["href"])
return result
def main():
list_href = []
list_content = []
url = "https://news.sbs.co.kr/news/newsflash.do?plink=GNB&cooper=SBSNEWS"
req = requests.get(url)
soup = BeautifulSoup(req.text, "html.parser")
list_href = get_href(soup)
print(list_href)
for url in list_href :
href_req = requests.get(url)
href_soup = BeautifulSoup(href_req.text, "html.parser")
result = crawling(href_soup)
list_content.append(result)
print(list_content)
if __name__ == "__main__":
main()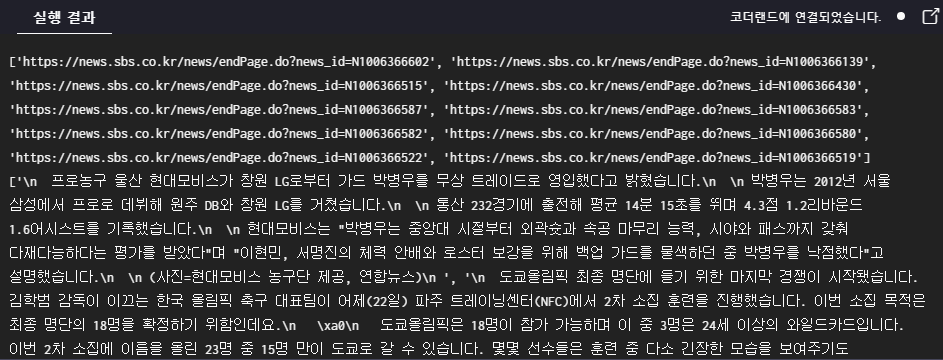
728x90
반응형
'Python > 크롤링' 카테고리의 다른 글
| 파이썬 크롤링 실습 - 영화 리뷰 추출하기 (0) | 2021.07.04 |
|---|---|
| 파이썬 크롤링 실습 - 네이버 뉴스 섹션들 기사 내용 추출하기 (0) | 2021.07.03 |
| 파이썬 크롤링 실습 - 네이버 뉴스 섹션들 기사 링크 추출하기 (0) | 2021.07.02 |
| 파이썬 크롤링 실습 - 네이트 최신뉴스 링크 수집하기 (0) | 2021.06.30 |
| 파이썬 크롤링 실습 - 뉴스기사 링크 수집하기 (0) | 2021.06.29 |
| 파이썬 크롤링 실습 - 여러 페이지의 기사 제목 수집하기 (0) | 2021.06.28 |
| 파이썬 크롤링 - HTML 태그 속성 (0) | 2021.06.27 |
'Python/크롤링' 관련 글
more




댓글