
DevSSOM
파이썬 크롤링 - 간단한 실습 : 네이버 헤드 뉴스 찾기 본문
반응형
네이버 헤드 뉴스 찾기
이번 실습에서는 네이버 홈페이지에서 표시되는 헤드라인 뉴스를 전부 크롤링하여 출력해보고자 함. 해야할 것에 맞춰 올바른 코드 작성하기.

위 사진의 빨간 상자 부분이 헤드 뉴스. 출력 예시는 아래처럼.
[헤드뉴스1, 헤드뉴스2, 헤드뉴스3, ———]
해야할 것
- 주어진 코드는 main 함수와 crawling 함수가 있음.
- main 함수에서는 crawling 함수의 결과값을 출력. main 함수를 직접 수정하실 필요는 없음.
- crawling 함수를 올바르게 구현해봐.
- crawling 함수는 네이버 메인 페이지의 헤드 뉴스를 찾고, 그것들의 제목을 담고 있는 리스트를 반환해야 함.
팁
- list.append() : 리스트의 맨 뒤에 요소를 추가하는 파이썬 메소드입니다.
- soup.find() : BeautifulSoup 객체에서 특정 태그를 찾기 위해 사용합니다.
- soup.find_all() : BeautifulSoup 객체에서 특정 태그 여러 개를 찾아 리스트 자료형으로 얻습니다.
import requests
from bs4 import BeautifulSoup
def crawling(soup) :
# soup 객체에서 추출해야 하는 정보를 찾고 반환해보기
result = []
return result
def main() :
custom_header = {
'referer' : 'https://www.naver.com/',
'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
url = "http://www.naver.com"
req = requests.get(url, headers = custom_header)
soup = BeautifulSoup(req.text, "html.parser")
# crawling 함수의 결과를 출력하기
print(crawling(soup))
if __name__ == "__main__" :
main()
>>>
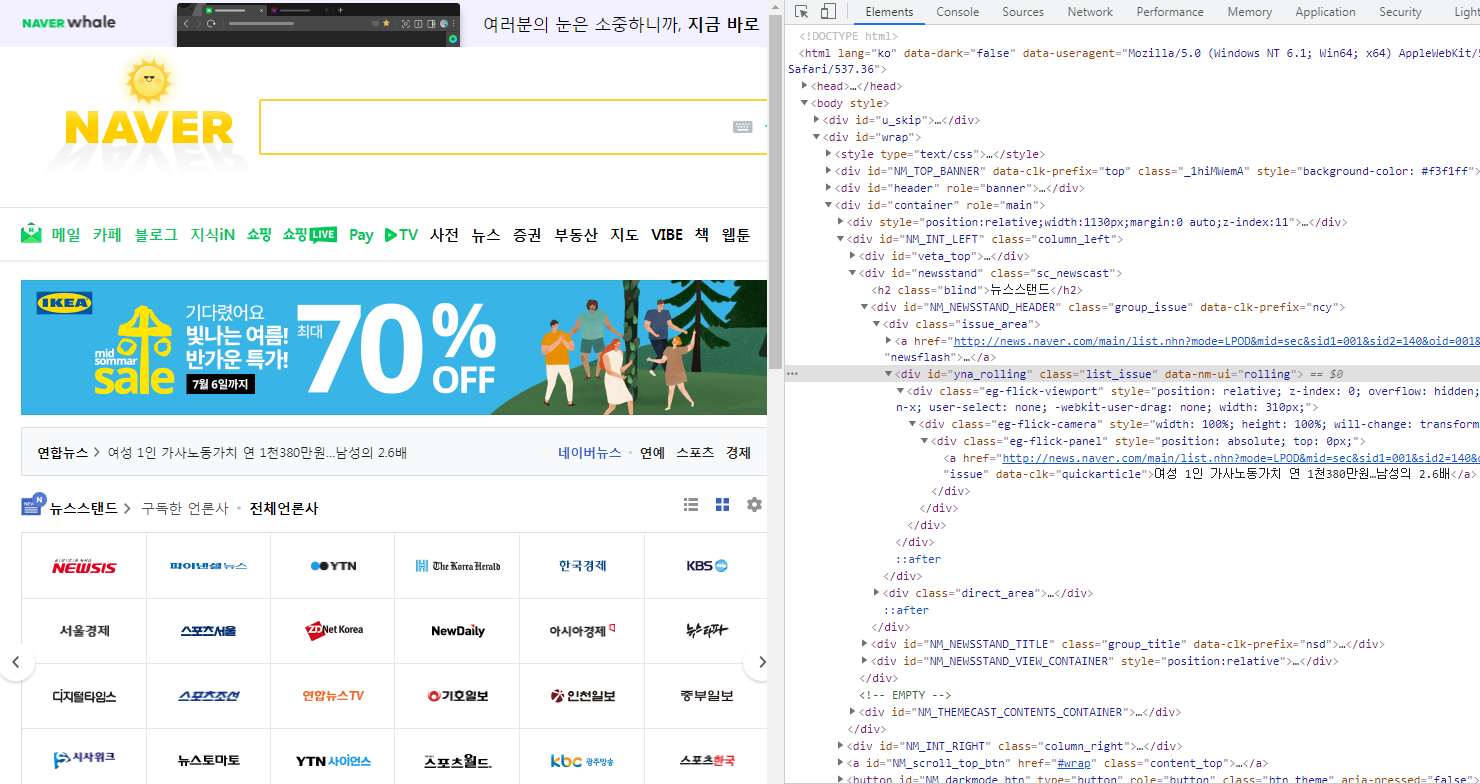
구글 개발자도구로 들어가서 연합뉴스 부분을 클릭하면 해당 HTML 소스로 가잖아. 거기서 저 뉴스 제목이 뜨는 곳을 보면, 회색 줄 부분이 해당됨. 저 부분을 크롤링 해보면,
def crawling(soup) :
# soup 객체에서 추출해야 하는 정보를 찾고 반환
result = []
div = soup.find("div", class_ = "list_issue")
print(div)
return result
div 태그 안에 있는 내용들이 출력이 되고 있어. 자세히 보면, a 태그에 각각의 뉴스 기사로 향하는 링크가 담겨있는데, 링크와 함께 뉴스의 제목이 나와. 그래서 이번엔 이 div의 모든 a 태그를 출력해보면
def crawling(soup) :
# soup 객체에서 추출해야 하는 정보를 찾고 반환
result = []
div = soup.find("div", class_ = "list_issue")
print(div.find_all("a"))
return result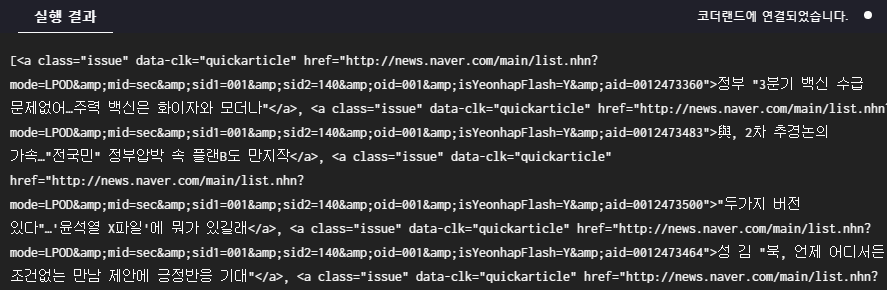
각각의 a태그가 리스트로 들어있는걸 볼 수 있음. 여기서 리스트에 들어있는 애들을 한 줄 한 줄 꺼내주고, 뉴스 제목들 텍스트만 출력하려면
def crawling(soup) :
# soup 객체에서 추출해야 하는 정보를 찾고 반환
result = []
div = soup.find("div", class_ = "list_issue")
for a in div.find_all("a") : # 각각의 줄에 a 태그가 출력이 되고
print(a.get_text())
return result
이걸 또 result라는 변수에 담아서 반환해주려면
def crawling(soup) :
# soup 객체에서 추출해야 하는 정보를 찾고 반환
result = []
div = soup.find("div", class_ = "list_issue")
for a in div.find_all("a") :
result.append(a.get_text())
return result
그러면 이렇게 리스트에 뉴스 제목들이 담겨서 출력되게 됨.
최종 코드
import requests
from bs4 import BeautifulSoup
def crawling(soup) :
# soup 객체에서 추출해야 하는 정보를 찾고 반환
result = []
div = soup.find("div", class_ = "list_issue")
for a in div.find_all("a") :
result.append(a.get_text())
return result
def main() :
custom_header = {
'referer' : 'https://www.naver.com/',
'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
url = "http://www.naver.com"
req = requests.get(url, headers = custom_header)
soup = BeautifulSoup(req.text, "html.parser")
# crawling 함수의 결과를 출력
print(crawling(soup))
if __name__ == "__main__" :
main()
728x90
반응형
'Python > 크롤링' 카테고리의 다른 글
| 파이썬 크롤링 - HTML 태그 속성 (0) | 2021.06.27 |
|---|---|
| 파이썬 크롤링 - 쿼리 개념 (0) | 2021.06.26 |
| 파이썬 크롤링 - 간단한 실습 : 네이트 판 댓글 수집 (1) | 2021.06.25 |
| 파이썬 크롤링 - 간단한 실습 : 영화 리뷰 수집 (0) | 2021.06.24 |
| 파이썬 크롤링 - 간단한 실습 : 벅스뮤직 음원차트 추출 (0) | 2021.06.23 |
| 파이썬 크롤링 - 간단한 실습 : 네이버 뉴스 헤드라인 추출 (0) | 2021.06.22 |
| 파이썬 크롤링 - BeautifulSoup 기본 개념 (0) | 2021.06.21 |
'Python/크롤링' 관련 글
more



댓글